2: IceNet Pipeline usage#
Context#
Purpose#
The first notebook demonstrated the use of high level command-line interfaces (CLI) of the IceNet library to download, process, train and predict from end to end.
Now that you have gone through the basic steps of running the IceNet model via the CLI, you may wish to establish a framework to run the model automatically for end-to-end runs. This is often called a Pipeline. A Pipeline can schedule ongoing model runs or run multiple model variations simultaneously.
This notebook illustrates the use of helper scripts from the IceNet pipeline repository for testing and producing operational forecasts.
Please do go through the first notebook before proceeding with this, as the data download exists outside of the pipeline, and this is covered in detail in the first notebook. However, even so, this notebook has been designed to be run independent of other notebooks in this repository.
This demonstrator notebook has been run on the British Antarctic Survey in-house HPC, however, the pipeline is by no means limited to running solely on HPCs.
Highlights#
The key features of an end to end run are:
Note: Steps 3, 4 and 5 are within the IceNet pipeline.
Contributions#
Notebook#
James Byrne (author)
Bryn Noel Ubald (co-author)
Matthew Gascoyne (co-author)
Please raise issues in this repository to suggest updates to this notebook!
Contact me at jambyr <at> bas.ac.uk for anything else…
Modelling codebase#
James Byrne (code author), Bryn Noel Ubald (code author), Tom Andersson (science author)
Modelling publications#
Andersson, T.R., Hosking, J.S., Pérez-Ortiz, M. et al. Seasonal Arctic sea ice forecasting with probabilistic deep learning. Nat Commun 12, 5124 (2021). https://doi.org/10.1038/s41467-021-25257-4
Involved organisations#
The Alan Turing Institute and British Antarctic Survey
1. Introduction#
CLI vs Library vs Pipeline usage#
The IceNet package is designed to support automated runs from end to end by exposing the CLI operations demonstrated in the first notebook. These are simple wrappers around the library itself, and any step of this can be undertaken manually or programmatically by inspecting the relevant endpoints.
IceNet can be run in a number of ways: from the command line, the python interface, or as a pipeline.
The rule of thumb to follow:
Use the pipeline repository if you want to run the end to end IceNet processing out of the box.
Adapt or customise this process using
icenet_*commands described in this notebook and in the scripts contained in the pipeline repo.For ultimate customisation, you can interact with the IceNet repository programmatically (which is how the CLI commands operate.) For more information look at the IceNet CLI implementations and the library notebook, along with the library documentation.
Using the Pipeline#
Now that you have gone through the basic steps of running the IceNet model via the high-level CLI commands, you may wish to establish a framework to run the model automatically for end-to-end runs. This is often called a Pipeline. A Pipeline can schedule ongoing model runs or run multiple model variations simultaneously. The pipeline is driven by a series of bash scripts, and an environmental ENVS configuration file.
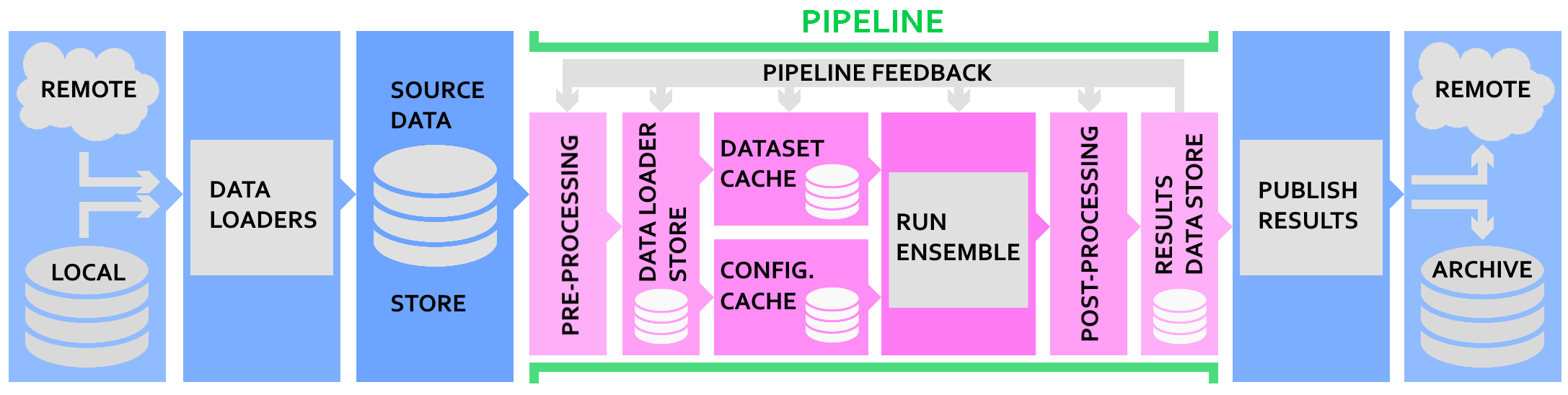
To automatically produce daily IceNet forecasts we train multiple variations of the model, each with different starting conditions. We call this ensemble training. Then we run predictions for each model variation, producing a mean and error across the whole model ensemble. This captures some of the model uncertainty.
Data#
This assumes that you have a data store in a data/ folder (This can be the same as the data/ directory generated when running through the first notebook). Since the data is common across pipelines, you do not need to redownload data that you have previously downloaded. It is recommended to symbolically link to a data store such that data is only downloaded when has not been downloaded previously.
Ensemble Running#
To do this, an icenet-pipeline repository is available. The icenet-pipeline offers the run_train_ensemble.sh and run_predict_ensemble.sh script which operates similarly to the icenet_train and icenet_predict CLI commands demonstrated in the first notebook from the IceNet library.
2. Setup#
Get the IceNet Pipeline#
Before progressing you will need to clone the icenet-pipeline repository. Assuming you have followed the directory structure from the first notebook:
git clone https://www.github.com/icenet-ai/icenet-pipeline.git green
ln -s green notebook-pipeline
cd icenet-notebooks
We clone a ‘fresh’ pipeline repository into a directory called ‘green’ (as an arbitrary way of identifying the fresh pipeline) and then symbolically link to it. This allows us to symbolically swap to another pipeline later if we want to.
my-icenet-project/ <--- we're in here!
├── data/
├── icenet-notebooks/
├── green/ <--- Clone of icenet-pipeline
└── notebook-pipeline@ <--- Symlink to the green/ `icenet-pipeline` repo we've just cloned into
# Viewing symbolically linked files.
!find .. -maxdepth 1 -type l -ls
139662625249 0 lrwxrwxrwx 1 bryald ailab 5 Feb 18 15:22 ../notebook-pipeline -> green
Configure the Pipeline#
Move into the notebook-pipeline directory.
import os
os.chdir("../notebook-pipeline")
!pwd
/data/hpcdata/users/bryald/git/icenet/icenet/green
The pipeline is driven by environmental variables that are defined within an ENVS file.
There is an example ENVS file (ENVS.example) in the ../notebook-pipeline directory which is what ENVS is symbolically linked to by default.
You can copy the ENVS.example file and create many variations to cover your usage scenario. Then, update the ENVS file symbolic link to the run you would like to go through.
As a demonstrator, we will change the existing my-icenet-project/notebook-pipeline/ENVS link that points to my-icenet-project/notebook-pipeline/ENVS.example.
We will instead point it to the example in this notebook repository after copying it over my-icenet-project/icenet-notebooks/ENVS.notebook_tutorial.
The ENVS files are typically collated within the notebook-pipeline repo, hence why we link the ENVS.notebook_tutorial in this repository to ENVS in the notebook-pipeline repository.
# Unlink the existing symoblic link (under `my-icenet-project/notebook-pipeline/ENVS`)
!unlink ENVS
# Point to the ENVS file from the icenet-notebooks repository (where this notebook is)
!ln -s ../icenet-notebooks/ENVS.notebook_tutorial ENVS
Before running through this notebook, please export the following variables to point to your icenet conda environment (if different to the default found in the ENVS file), as an example:
export ICENET_HOME=${HOME}/icenet/icenetv0.2.9
export ICENET_CONDA=${HOME}/conda-envs/icenet
This will overwrite the defaults within the ENVS file, and will be used by the pipeline.
# Looking at the symlinked files in the `notebook-pipeline` directory
!find . -maxdepth 1 -type l -ls
352250552559 0 lrwxrwxrwx 1 bryald ailab 7 Feb 18 15:33 ./data -> ../data
352248255940 0 lrwxrwxrwx 1 bryald ailab 42 Feb 18 15:40 ./ENVS -> ../icenet-notebooks/ENVS.notebook_tutorial
Download data before initiating pipeline#
As shown in the pipeline image at the top, the source data download is external to the pipeline since it is common across pipelines.
Hence, the same commands from the first notebook can be used to download the required data into a data store (if not previously downloaded) and symbolically linked into in the working directory before using the pipeline. Please check the first notebook for details regarding the usage of these commands.
Please note that you do not need to redownload data you have already downloaded previously (i.e., for date ranges you have previously downloaded into your data store).
Assuming you’ve run the first notebook, you’ve already downloaded the necessary data to the ../data directory, so, we can now symbolically link the data into our working directory. The code will skip over any previously downloaded date ranges. You can link to the datastore by running ln -s ../data.
!icenet_data_masks south
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_01.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_02.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_03.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_04.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_05.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_06.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_07.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_08.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_09.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_10.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_11.npy, already exists
[18-02-25 15:40:45 :INFO ] - Skipping ./data/masks/south/masks/active_grid_cell_mask_12.npy, already exists
!icenet_data_era5 south --vars uas,vas,tas,zg --levels ',,,500|250' 2020-1-1 2020-4-30
[18-02-25 15:40:48 :INFO ] - ERA5 Data Downloading
2025-02-18 15:40:48,730 INFO [2024-09-26T00:00:00] Watch our [Forum](https://forum.ecmwf.int/) for Announcements, news and other discussed topics.
[18-02-25 15:40:48 :INFO ] - [2024-09-26T00:00:00] Watch our [Forum](https://forum.ecmwf.int/) for Announcements, news and other discussed topics.
2025-02-18 15:40:48,731 WARNING [2024-06-16T00:00:00] CDS API syntax is changed and some keys or parameter names may have also changed. To avoid requests failing, please use the "Show API request code" tool on the dataset Download Form to check you are using the correct syntax for your API request.
[18-02-25 15:40:48 :WARNING ] - [2024-06-16T00:00:00] CDS API syntax is changed and some keys or parameter names may have also changed. To avoid requests failing, please use the "Show API request code" tool on the dataset Download Form to check you are using the correct syntax for your API request.
[18-02-25 15:40:48 :INFO ] - Building request(s), downloading and daily averaging from ERA5 API
[18-02-25 15:40:48 :INFO ] - Processing single download for uas @ None with 121 dates
[18-02-25 15:40:48 :INFO ] - Processing single download for vas @ None with 121 dates
[18-02-25 15:40:48 :INFO ] - Processing single download for tas @ None with 121 dates
[18-02-25 15:40:48 :INFO ] - Processing single download for zg @ 500 with 121 dates
[18-02-25 15:40:48 :INFO ] - Processing single download for zg @ 250 with 121 dates
[18-02-25 15:40:49 :INFO ] - No requested dates remain, likely already present
[18-02-25 15:40:49 :INFO ] - No requested dates remain, likely already present
[18-02-25 15:40:49 :INFO ] - No requested dates remain, likely already present
[18-02-25 15:40:49 :INFO ] - No requested dates remain, likely already present
[18-02-25 15:40:49 :INFO ] - No requested dates remain, likely already present
[18-02-25 15:40:49 :INFO ] - 0 daily files downloaded
[18-02-25 15:40:49 :INFO ] - No regrid batches to processing, moving on...
[18-02-25 15:40:49 :INFO ] - Rotating wind data prior to merging
[18-02-25 15:40:50 :INFO ] - Rotating wind data in ./data/era5/south/uas ./data/era5/south/vas
[18-02-25 15:40:50 :INFO ] - 0 files for uas
[18-02-25 15:40:50 :INFO ] - 0 files for vas
Note: We also make sure to also download sea-ice concentration data for the time period we’re predicting for (in addition to the training range).
In this case, the ENVS file defines the latest train date as being 2020-3-31, and the latest test date being 2020-4-2. Since we would like to forecast for 7 days (Also defined within the ENVS file under export FORECAST_DAYS=7), we should download up to 7 days after the end dates of train/validation/test.
This will also be of use when comparing the prediction data.
These do not have to be downloaded in separate date ranges, you can cover the entire period in one go (2019-12-29 2020-4-30), or use (e.g. 2019-12-29,2020-4-3 2020-3-31,2020-4-23) syntax. The download is split into multiple sections to also demonstrate that previously downloaded data will be skipped over. This is the same for the above ERA5 download.
# Date range for training (Adding 7 days forecast period to end date)
!icenet_data_sic south -d 2020-1-1 2020-4-7
# Date range for validation (Adding 7 days forecast period to end date)
!icenet_data_sic south -d 2020-4-3 2020-4-30
# Date range for test (Adding 7 days forecast period to end date)
# Note: Above date range already covers this, so this data will not be re-downloaded.
!icenet_data_sic south -d 2020-4-1 2020-4-9
[18-02-25 15:40:54 :INFO ] - OSASIF-SIC Data Downloading
[18-02-25 15:40:54 :INFO ] - Downloading SIC datafiles to .temp intermediates...
[18-02-25 15:40:55 :INFO ] - Excluding 121 dates already existing from 98 dates requested.
[18-02-25 15:40:55 :INFO ] - Opening for interpolation: ['./data/osisaf/south/siconca/2020.nc']
[18-02-25 15:40:55 :INFO ] - Processing 0 missing dates
[18-02-25 15:40:56 :INFO ] - OSASIF-SIC Data Downloading
[18-02-25 15:40:56 :INFO ] - Downloading SIC datafiles to .temp intermediates...
[18-02-25 15:40:57 :INFO ] - Excluding 121 dates already existing from 28 dates requested.
[18-02-25 15:40:57 :INFO ] - Opening for interpolation: ['./data/osisaf/south/siconca/2020.nc']
[18-02-25 15:40:57 :INFO ] - Processing 0 missing dates
[18-02-25 15:40:58 :INFO ] - OSASIF-SIC Data Downloading
[18-02-25 15:40:58 :INFO ] - Downloading SIC datafiles to .temp intermediates...
[18-02-25 15:40:59 :INFO ] - Excluding 121 dates already existing from 9 dates requested.
[18-02-25 15:40:59 :INFO ] - Opening for interpolation: ['./data/osisaf/south/siconca/2020.nc']
[18-02-25 15:40:59 :INFO ] - Processing 0 missing dates
3. Process#
The following command processes the downloaded data for the dates defined in the ENVS file.
This is equivalent to running icenet_process_era5, icenet_process_ora5, icenet_process_sic, icenet_process_metadata commands from the IceNet library (as demonstrated in the first notebook).
The arguments passed to these commands are obtained from the PROC_ARGS_* variables in the ENVS file.
And, the dates that are processed are defined by the following variables in the ENVS file:
TRAIN_START_*TRAIN_END_*VAL_START_*VAL_END_*TEST_START_*TEST_END_*
This only needs to be run once unless the above variables need to be changed. Hence, it can be run as a precursor to the pipeline if the processed data does not need to change.
!./run_data.sh south
CondaError: Run 'conda init' before 'conda activate'
[18-02-25 15:41:13 :INFO ] - Got 91 dates for train
[18-02-25 15:41:13 :INFO ] - Got 21 dates for val
[18-02-25 15:41:13 :INFO ] - Got 2 dates for test
[18-02-25 15:41:13 :INFO ] - Creating path: ./processed/tutorial_pipeline_south/era5
[18-02-25 15:41:13 :DEBUG ] - Setting range for linear trend steps based on 7
[18-02-25 15:41:13 :INFO ] - Processing 91 dates for train category
[18-02-25 15:41:13 :INFO ] - Including lag of 1 days
[18-02-25 15:41:13 :INFO ] - Including lead of 93 days
[18-02-25 15:41:13 :DEBUG ] - Globbing train from ./data/era5/south/**/[12]*.nc
[18-02-25 15:41:13 :DEBUG ] - Globbed 376 files
[18-02-25 15:41:13 :DEBUG ] - Create structure of 376 files
[18-02-25 15:41:13 :INFO ] - Processing 21 dates for val category
[18-02-25 15:41:13 :INFO ] - Including lag of 1 days
[18-02-25 15:41:13 :INFO ] - Including lead of 93 days
[18-02-25 15:41:13 :DEBUG ] - Globbing val from ./data/era5/south/**/[12]*.nc
[18-02-25 15:41:13 :DEBUG ] - Globbed 376 files
[18-02-25 15:41:13 :DEBUG ] - Create structure of 376 files
[18-02-25 15:41:13 :INFO ] - Processing 2 dates for test category
[18-02-25 15:41:13 :INFO ] - Including lag of 1 days
[18-02-25 15:41:13 :INFO ] - Including lead of 93 days
[18-02-25 15:41:13 :DEBUG ] - Globbing test from ./data/era5/south/**/[12]*.nc
[18-02-25 15:41:13 :DEBUG ] - Globbed 376 files
[18-02-25 15:41:13 :DEBUG ] - Create structure of 376 files
[18-02-25 15:41:13 :INFO ] - Got 2 files for psl
[18-02-25 15:41:13 :INFO ] - Got 2 files for ta500
[18-02-25 15:41:13 :INFO ] - Got 2 files for tas
[18-02-25 15:41:13 :INFO ] - Got 2 files for tos
[18-02-25 15:41:13 :INFO ] - Got 2 files for uas
[18-02-25 15:41:13 :INFO ] - Got 2 files for vas
[18-02-25 15:41:13 :INFO ] - Got 2 files for zg250
[18-02-25 15:41:13 :INFO ] - Got 2 files for zg500
[18-02-25 15:41:13 :INFO ] - Opening files for uas
[18-02-25 15:41:13 :DEBUG ] - Files: ['./data/era5/south/uas/2019.nc', './data/era5/south/uas/2020.nc']
[18-02-25 15:41:13 :DEBUG ] - eccodes lib search: trying to find binary wheel
[18-02-25 15:41:13 :DEBUG ] - eccodes lib search: looking in /data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/eccodes.libs
[18-02-25 15:41:13 :DEBUG ] - eccodes lib search: returning wheel library from /data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/eccodes.libs/libeccodes-35258663.so
[18-02-25 15:41:13 :DEBUG ] - eccodes lib search: versions: {'eccodes': '2.38.3'}
[18-02-25 15:41:14 :DEBUG ] - GDAL data found in package: path='/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/rasterio/gdal_data'.
[18-02-25 15:41:14 :DEBUG ] - PROJ data found in package: path='/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/rasterio/proj_data'.
[18-02-25 15:41:14 :DEBUG ] - Files have var names uas which will be renamed to uas
[18-02-25 15:41:14 :DEBUG ] - 731 dates in da
[18-02-25 15:41:14 :INFO ] - Filtered to 731 units long based on configuration requirements
[18-02-25 15:41:16 :DEBUG ] - No pre normalisation implemented for uas
[18-02-25 15:41:16 :INFO ] - Normalising uas
[18-02-25 15:41:16 :DEBUG ] - Generating norm-scaling min-max from 91 training dates
[18-02-25 15:41:17 :DEBUG ] - No post normalisation implemented for uas
[18-02-25 15:41:18 :DEBUG ] - Adding uas file: ./processed/tutorial_pipeline_south/era5/south/uas/uas_abs.nc
[18-02-25 15:41:18 :INFO ] - Opening files for vas
[18-02-25 15:41:18 :DEBUG ] - Files: ['./data/era5/south/vas/2019.nc', './data/era5/south/vas/2020.nc']
[18-02-25 15:41:18 :DEBUG ] - Files have var names vas which will be renamed to vas
[18-02-25 15:41:18 :DEBUG ] - 731 dates in da
[18-02-25 15:41:18 :INFO ] - Filtered to 731 units long based on configuration requirements
[18-02-25 15:41:20 :DEBUG ] - No pre normalisation implemented for vas
[18-02-25 15:41:20 :INFO ] - Normalising vas
[18-02-25 15:41:20 :DEBUG ] - Generating norm-scaling min-max from 91 training dates
[18-02-25 15:41:21 :DEBUG ] - No post normalisation implemented for vas
[18-02-25 15:41:21 :DEBUG ] - Adding vas file: ./processed/tutorial_pipeline_south/era5/south/vas/vas_abs.nc
[18-02-25 15:41:21 :INFO ] - Opening files for zg500
[18-02-25 15:41:21 :DEBUG ] - Files: ['./data/era5/south/zg500/2019.nc', './data/era5/south/zg500/2020.nc']
[18-02-25 15:41:21 :DEBUG ] - Files have var names zg500 which will be renamed to zg500
[18-02-25 15:41:21 :DEBUG ] - 731 dates in da
[18-02-25 15:41:21 :INFO ] - Filtered to 731 units long based on configuration requirements
[18-02-25 15:41:21 :INFO ] - Generating climatology ./processed/tutorial_pipeline_south/era5/south/params/climatology.zg500
[18-02-25 15:41:22 :WARNING ] - We don't have a full climatology (1,2,3) compared with data (1,2,3,4,5,6,7,8,9,10,11,12)
[18-02-25 15:41:23 :DEBUG ] - No pre normalisation implemented for zg500
[18-02-25 15:41:23 :INFO ] - Normalising zg500
[18-02-25 15:41:23 :DEBUG ] - Generating norm-scaling min-max from 91 training dates
[18-02-25 15:41:24 :DEBUG ] - No post normalisation implemented for zg500
[18-02-25 15:41:24 :DEBUG ] - Adding zg500 file: ./processed/tutorial_pipeline_south/era5/south/zg500/zg500_anom.nc
[18-02-25 15:41:24 :INFO ] - Opening files for zg250
[18-02-25 15:41:24 :DEBUG ] - Files: ['./data/era5/south/zg250/2019.nc', './data/era5/south/zg250/2020.nc']
[18-02-25 15:41:24 :DEBUG ] - Files have var names zg250 which will be renamed to zg250
[18-02-25 15:41:24 :DEBUG ] - 731 dates in da
[18-02-25 15:41:24 :INFO ] - Filtered to 731 units long based on configuration requirements
[18-02-25 15:41:24 :INFO ] - Generating climatology ./processed/tutorial_pipeline_south/era5/south/params/climatology.zg250
[18-02-25 15:41:25 :WARNING ] - We don't have a full climatology (1,2,3) compared with data (1,2,3,4,5,6,7,8,9,10,11,12)
[18-02-25 15:41:26 :DEBUG ] - No pre normalisation implemented for zg250
[18-02-25 15:41:26 :INFO ] - Normalising zg250
[18-02-25 15:41:26 :DEBUG ] - Generating norm-scaling min-max from 91 training dates
[18-02-25 15:41:27 :DEBUG ] - No post normalisation implemented for zg250
[18-02-25 15:41:28 :DEBUG ] - Adding zg250 file: ./processed/tutorial_pipeline_south/era5/south/zg250/zg250_anom.nc
[18-02-25 15:41:28 :INFO ] - Writing configuration to ./loader.tutorial_pipeline_south.json
[18-02-25 15:41:32 :INFO ] - Got 91 dates for train
[18-02-25 15:41:32 :INFO ] - Got 21 dates for val
[18-02-25 15:41:32 :INFO ] - Got 2 dates for test
[18-02-25 15:41:32 :INFO ] - Creating path: ./processed/tutorial_pipeline_south/osisaf
[18-02-25 15:41:32 :DEBUG ] - Setting range for linear trend steps based on 7
[18-02-25 15:41:32 :INFO ] - Processing 91 dates for train category
[18-02-25 15:41:32 :INFO ] - Including lag of 1 days
[18-02-25 15:41:32 :INFO ] - Including lead of 93 days
[18-02-25 15:41:32 :DEBUG ] - Globbing train from ./data/osisaf/south/**/[12]*.nc
[18-02-25 15:41:32 :DEBUG ] - Globbed 1 files
[18-02-25 15:41:32 :DEBUG ] - Create structure of 1 files
[18-02-25 15:41:32 :INFO ] - No data found for 2019-12-31, outside data boundary perhaps?
[18-02-25 15:41:32 :INFO ] - Processing 21 dates for val category
[18-02-25 15:41:32 :INFO ] - Including lag of 1 days
[18-02-25 15:41:32 :INFO ] - Including lead of 93 days
[18-02-25 15:41:32 :DEBUG ] - Globbing val from ./data/osisaf/south/**/[12]*.nc
[18-02-25 15:41:32 :DEBUG ] - Globbed 1 files
[18-02-25 15:41:32 :DEBUG ] - Create structure of 1 files
[18-02-25 15:41:32 :INFO ] - Processing 2 dates for test category
[18-02-25 15:41:32 :INFO ] - Including lag of 1 days
[18-02-25 15:41:32 :INFO ] - Including lead of 93 days
[18-02-25 15:41:32 :DEBUG ] - Globbing test from ./data/osisaf/south/**/[12]*.nc
[18-02-25 15:41:32 :DEBUG ] - Globbed 1 files
[18-02-25 15:41:32 :DEBUG ] - Create structure of 1 files
[18-02-25 15:41:32 :INFO ] - Got 1 files for siconca
[18-02-25 15:41:32 :INFO ] - Opening files for siconca
[18-02-25 15:41:32 :DEBUG ] - Files: ['./data/osisaf/south/siconca/2020.nc']
[18-02-25 15:41:32 :DEBUG ] - eccodes lib search: trying to find binary wheel
[18-02-25 15:41:32 :DEBUG ] - eccodes lib search: looking in /data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/eccodes.libs
[18-02-25 15:41:32 :DEBUG ] - eccodes lib search: returning wheel library from /data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/eccodes.libs/libeccodes-35258663.so
[18-02-25 15:41:32 :DEBUG ] - eccodes lib search: versions: {'eccodes': '2.38.3'}
[18-02-25 15:41:32 :DEBUG ] - GDAL data found in package: path='/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/rasterio/gdal_data'.
[18-02-25 15:41:32 :DEBUG ] - PROJ data found in package: path='/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/rasterio/proj_data'.
[18-02-25 15:41:33 :DEBUG ] - Files have var names ice_conc which will be renamed to siconca
[18-02-25 15:41:33 :DEBUG ] - 121 dates in da
[18-02-25 15:41:33 :INFO ] - Filtered to 121 units long based on configuration requirements
[18-02-25 15:41:33 :DEBUG ] - ./data/masks already exists
[18-02-25 15:41:33 :INFO ] - Generating trend data up to 7 steps ahead for 121 dates
[18-02-25 15:41:33 :INFO ] - Generating 127 trend dates
[18-02-25 15:41:34 :DEBUG ] - ./data/masks already exists
[18-02-25 15:41:38 :INFO ] - Writing new trend cache for siconca
[18-02-25 15:41:38 :DEBUG ] - Adding siconca file: ./processed/tutorial_pipeline_south/osisaf/south/siconca/siconca_linear_trend.nc
[18-02-25 15:41:38 :INFO ] - No normalisation for siconca
[18-02-25 15:41:38 :DEBUG ] - No post normalisation implemented for siconca
[18-02-25 15:41:38 :DEBUG ] - Adding siconca file: ./processed/tutorial_pipeline_south/osisaf/south/siconca/siconca_abs.nc
[18-02-25 15:41:38 :INFO ] - Loading configuration ./loader.tutorial_pipeline_south.json
[18-02-25 15:41:38 :INFO ] - Writing configuration to ./loader.tutorial_pipeline_south.json
[18-02-25 15:41:41 :INFO ] - Creating path: ./processed/tutorial_pipeline_south/meta
[18-02-25 15:41:42 :INFO ] - Loading configuration ./loader.tutorial_pipeline_south.json
[18-02-25 15:41:42 :INFO ] - Writing configuration to ./loader.tutorial_pipeline_south.json
[18-02-25 15:41:45 :INFO ] - Got 0 dates for train
[18-02-25 15:41:45 :INFO ] - Got 0 dates for val
[18-02-25 15:41:45 :INFO ] - Got 0 dates for test
[18-02-25 15:41:45 :INFO ] - Creating path: ./network_datasets/tutorial_pipeline_south
[18-02-25 15:41:45 :INFO ] - Loading configuration loader.tutorial_pipeline_south.json
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to uas_abs channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to vas_abs channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to siconca_abs channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to zg250_anom channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to zg500_anom channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to siconca_linear_trend channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to cos channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to land channel
[18-02-25 15:41:45 :DEBUG ] - Adding 1 to sin channel
[18-02-25 15:41:45 :DEBUG ] - Channel quantities deduced:
{'cos': 1,
'land': 1,
'siconca_abs': 1,
'siconca_linear_trend': 7,
'sin': 1,
'uas_abs': 1,
'vas_abs': 1,
'zg250_anom': 1,
'zg500_anom': 1}
Total channels: 15
[18-02-25 15:41:45 :DEBUG ] - ./data/masks already exists
[18-02-25 15:41:45 :DEBUG ] - Using selector: EpollSelector
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/node.py:187: UserWarning: Port 8888 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 44768 instead
warnings.warn(
[18-02-25 15:41:46 :INFO ] - Dashboard at localhost:8888
[18-02-25 15:41:46 :INFO ] - Using dask client <Client: 'tcp://127.0.0.1:45212' processes=8 threads=8, memory=503.20 GiB>
[18-02-25 15:41:47 :INFO ] - 91 train dates to process, generating cache data.
2025-02-18 15:41:50,850 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 13, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 13, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 13, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 13, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 13, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:41:57,926 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 12, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 12, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 12, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 12, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 12, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:41:59,423 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 22, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 22, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 22, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 22, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 22, 0, 0)}
2025-02-18 15:42:00,057 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 4, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 4, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 4, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 4, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 4, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:00,340 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('astype-ac07afc5678ef766d38010ceed63954d', 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('astype-ac07afc5678ef766d38010ceed63954d', 0, 0)->('array-getitem-astype-ac07afc5678ef766d38010ceed63954d', 0, 0))
new run_spec: Alias(('astype-ac07afc5678ef766d38010ceed63954d', 0, 0)->('getitem-astype-ac07afc5678ef766d38010ceed63954d', 0, 0))
old dependencies: {('array-getitem-astype-ac07afc5678ef766d38010ceed63954d', 0, 0)}
new dependencies: {('getitem-astype-ac07afc5678ef766d38010ceed63954d', 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:01,119 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 16, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 16, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 16, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 16, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 16, 0, 0)}
2025-02-18 15:42:01,207 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 18, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 18, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 18, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 18, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 18, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000000.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000001.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000002.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000003.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000004.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000005.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000006.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000007.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000008.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000009.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000010.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000011.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000012.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000013.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000014.tfrecord
[18-02-25 15:42:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000015.tfrecord
2025-02-18 15:42:11,735 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 39, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 39, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 39, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 39, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 39, 0, 0)}
2025-02-18 15:42:11,774 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 35, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 35, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 35, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 35, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 35, 0, 0)}
2025-02-18 15:42:11,958 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 53, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 53, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 53, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 53, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 53, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:13,760 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('astype-8edca25275ac5fe21814770f6825e20b', 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: processing
old run_spec: Alias(('astype-8edca25275ac5fe21814770f6825e20b', 0, 0)->('array-getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0))
new run_spec: Alias(('astype-8edca25275ac5fe21814770f6825e20b', 0, 0)->('getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0))
old dependencies: {('array-getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0)}
new dependencies: {('getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:14,532 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)->('getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0))
new run_spec: Alias(('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)->('array-getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0))
old dependencies: {('getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)}
new dependencies: {('array-getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:14,669 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: processing
old run_spec: Alias(('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)->('getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0))
new run_spec: Alias(('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)->('array-getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0))
old dependencies: {('getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)}
new dependencies: {('array-getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:16,029 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('astype-8edca25275ac5fe21814770f6825e20b', 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('astype-8edca25275ac5fe21814770f6825e20b', 0, 0)->('array-getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0))
new run_spec: Alias(('astype-8edca25275ac5fe21814770f6825e20b', 0, 0)->('getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0))
old dependencies: {('array-getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0)}
new dependencies: {('getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0)}
2025-02-18 15:42:17,322 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 36, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 36, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 36, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 36, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 36, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:18,711 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 52, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 52, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 52, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 52, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 52, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:20,143 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 58, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 58, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 58, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 58, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 58, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:21,048 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('astype-8edca25275ac5fe21814770f6825e20b', 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('astype-8edca25275ac5fe21814770f6825e20b', 0, 0)->('array-getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0))
new run_spec: Alias(('astype-8edca25275ac5fe21814770f6825e20b', 0, 0)->('getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0))
old dependencies: {('array-getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0)}
new dependencies: {('getitem-astype-8edca25275ac5fe21814770f6825e20b', 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:21,538 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 42, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 42, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 42, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 42, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 42, 0, 0)}
2025-02-18 15:42:21,644 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 38, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 38, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 38, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 38, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 38, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:23,058 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)->('getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0))
new run_spec: Alias(('astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)->('array-getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0))
old dependencies: {('getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)}
new dependencies: {('array-getitem-astype-bbd1124cd4ebdf229756b011d5b455c2', 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000016.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000017.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000018.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000019.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000020.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000021.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000022.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000023.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000024.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000025.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000026.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000027.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000028.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000029.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000030.tfrecord
[18-02-25 15:42:31 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000031.tfrecord
2025-02-18 15:42:32,945 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 73, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 73, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 73, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 73, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 73, 0, 0)}
2025-02-18 15:42:33,305 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 67, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: processing
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 67, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 67, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 67, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 67, 0, 0)}
2025-02-18 15:42:33,596 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 79, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: processing
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 79, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 79, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 79, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 79, 0, 0)}
2025-02-18 15:42:33,683 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 81, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 81, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 81, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 81, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 81, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:38,148 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0))
new run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0) getter(...)>
old dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0)}
new dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:40,081 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0))
new run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0) getter(...)>
old dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 74, 0, 0)}
new dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
2025-02-18 15:42:41,722 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 76, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 76, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 76, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 76, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 76, 0, 0)}
2025-02-18 15:42:41,738 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 78, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 78, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 78, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 78, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 78, 0, 0)}
2025-02-18 15:42:41,859 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 86, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 86, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 86, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 86, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 86, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000032.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000033.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000034.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000035.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000036.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000037.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000038.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000039.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000040.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000041.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000042.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000043.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000044.tfrecord
[18-02-25 15:42:53 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/train/00000045.tfrecord
[18-02-25 15:42:53 :INFO ] - 21 val dates to process, generating cache data.
2025-02-18 15:42:54,898 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 108, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: processing
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 108, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 108, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 108, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 108, 0, 0)}
2025-02-18 15:42:54,987 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 110, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 110, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 110, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 110, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 110, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:42:58,029 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 95, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 95, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 95, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 95, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 95, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:43:02,325 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 111, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 111, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 111, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 111, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 111, 0, 0)}
2025-02-18 15:43:02,427 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 109, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 109, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 109, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 109, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 109, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2025-02-18 15:43:04,067 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 107, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 107, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 107, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 107, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 107, 0, 0)}
2025-02-18 15:43:04,135 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 101, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 101, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 101, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 101, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 101, 0, 0)}
2025-02-18 15:43:04,159 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 103, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 103, 0, 0) getter(...)>
new run_spec: Alias(('open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 103, 0, 0)->('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 103, 0, 0))
old dependencies: {'original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac'}
new dependencies: {('original-open_dataset-siconca_abs-91ef2c2db1f71f7aeb21e08939b695ac', 103, 0, 0)}
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000000.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000001.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000002.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000003.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000004.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000005.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000006.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000007.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000008.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000009.tfrecord
[18-02-25 15:43:10 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/val/00000010.tfrecord
[18-02-25 15:43:10 :INFO ] - 2 test dates to process, generating cache data.
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/data/hpcdata/users/bryald/miniconda3/envs/icenet0.2.9_dev/lib/python3.11/site-packages/distributed/client.py:3370: UserWarning: Sending large graph of size 22.10 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
[18-02-25 15:43:17 :INFO ] - Finished output ./network_datasets/tutorial_pipeline_south/south/test/00000000.tfrecord
[18-02-25 15:43:17 :INFO ] - Average sample generation time: 7.675325972992077
[18-02-25 15:43:17 :INFO ] - Writing configuration to ./dataset_config.tutorial_pipeline_south.json
4. Train#
For producing forecasts in the described pipeline we actually run a set of models using the model-ensembler tool and as such there are convenience scripts for doing this as part of the end to end run.
This requires the model-ensembler (pip install model-ensembler) module to be installed.
Note that the model-ensembler will submit jobs and to configure the job scripts, you can access the templates that are used to generate them in the .yaml (in particular train.tmpl.yaml for the training ensemble jobs) files in the ensemble/ folder of the clone of the icenet-pipeline repository.
Many of the arguments for the following command are equivalent to the icenet_train command. However, the -n filters factor is actually -f in this example and we have additional arguments -n for the node to run on, -p for the pre_run script to use and -j for the number of simultaneous runs to execute on the SLURM cluster we use at BAS. However, these arguments are not necessarily required for other clusters, nor is the model-ensembler limited to running on SLURM (it can, at present, also run locally.)
The pipeline repository shell scripts that provide this functionality are easily adaptable, as well as the ensemble itself which is stored in the pipeline repository under /ensemble/.
Please review the -h help option for the script to gain further insight the options available.
!./run_train_ensemble.sh --help
Usage ./run_train_ensemble.sh LOADER DATASET NAME
The optional arguments (Some are not defined in this example):
argument | description | value |
|---|---|---|
-b | Batch size | - |
-d | Run locally instead of submitting SLURM jobs | - |
-e | Number of epochs to train for | 10 |
-f | Scale the neural network channel sizes by this factor (reduces network size, priority over ENVS definition) | 0.6 |
-m | Memory required | 64gb |
-n | Node to run on | - |
-p | pre_run script to use | - |
-q | Maximum queue size | 4 |
-r | Seed values for ensemble members (determines no. of ensemble members, overrides values in ENVS if specified) | - |
-j | No. of simultaneous runs to execute on the SLURM cluster | 5 |
The positional arguments:
argument | description | value |
|---|---|---|
LOADER | Name of loader: loader.{LOADER}.json | tutorial_pipeline_south |
DATASET | Name of dataset: dataset_config.{LOADER}.json | tutorial_pipeline_south |
NAME | Neural network output name | tutorial_south_ensemble |
The loader and dataset names are defined by the prefix in the ENVS file. The hemisphere is appended to the defined string, so the following in the ENVS.notebook_tutorial file becomes “tutorial_pipeline_south”.
PREFIX="TUTORIAL_PIPELINE"
# Positional Arguments
# argument 1: The loader json file: loader.tutorial_pipeline_south.json
# argument 2: The dataset json file: dataset_config.tutorial_pipeline_south.json
# argument 3: The trained network name: tutorial_south_ensemble
!./run_train_ensemble.sh -e 10 -f 0.6 -m 64gb -q 4 -j 5 tutorial_pipeline_south tutorial_pipeline_south tutorial_south_ensemble
ARGS: -e 10 -f 0.6 -m 64gb -q 4 -j 5 tutorial_pipeline_south tutorial_pipeline_south tutorial_south_ensemble
ARGS = -x arg_epochs=10 arg_filter_factor=0.6 mem=64gb arg_queue=4 , Leftovers: tutorial_pipeline_south tutorial_pipeline_south tutorial_south_ensemble
No. of ensemble members: 2
Ensemble members: 42,46
Running model_ensemble ./tmp.9ywAtKjEaN.train slurm -x arg_epochs=10 arg_filter_factor=0.6 mem=64gb arg_queue=4
[18-02-25 15:44:46 :INFO ] - Model Ensemble Runner
[18-02-25 15:44:46 :INFO ] - Validated configuration file ./tmp.9ywAtKjEaN.train successfully
[18-02-25 15:44:46 :INFO ] - Importing model_ensembler.cluster.slurm
[18-02-25 15:44:46 :INFO ] - Running batcher
[18-02-25 15:44:46 :INFO ] - Running command: mkdir -p ./results/networks
[18-02-25 15:44:46 :INFO ] - Start batch: 2025-02-18 15:44:46.250803
[18-02-25 15:44:46 :INFO ] - Running cycle 1
[18-02-25 15:44:46 :INFO ] - Start run tutorial_south_ensemble-0 at 2025-02-18 15:44:46.252327
[18-02-25 15:44:46 :INFO ] - rsync -aXE ../template/ /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble/tutorial_south_ensemble-0/
[18-02-25 15:44:46 :INFO ] - Start run tutorial_south_ensemble-1 at 2025-02-18 15:44:46.256184
[18-02-25 15:44:46 :INFO ] - rsync -aXE ../template/ /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble/tutorial_south_ensemble-1/
[18-02-25 15:44:46 :INFO ] - Templating /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble/tutorial_south_ensemble-0/icenet_train.sh.j2 to /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble/tutorial_south_ensemble-0/icenet_train.sh
[18-02-25 15:44:46 :INFO ] - Templating /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble/tutorial_south_ensemble-1/icenet_train.sh.j2 to /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble/tutorial_south_ensemble-1/icenet_train.sh
[18-02-25 15:44:46 :INFO ] - Submitted job with ID 6288960
[18-02-25 15:44:46 :INFO ] - Submitted job with ID 6288961
[18-02-25 15:44:46 :WARNING ] - Could not retrieve job from list
[18-02-25 15:44:46 :WARNING ] - Could not retrieve job from list
[18-02-25 15:47:17 :INFO ] - tutorial_south_ensemble-1 monitor got state COMPLETED for job 6288961
[18-02-25 15:47:17 :INFO ] - End run tutorial_south_ensemble-1 at 2025-02-18 15:47:17.094795
[18-02-25 15:47:17 :INFO ] - tutorial_south_ensemble-0 monitor got state COMPLETED for job 6288960
[18-02-25 15:47:17 :INFO ] - End run tutorial_south_ensemble-0 at 2025-02-18 15:47:17.095451
[18-02-25 15:47:17 :INFO ] - Running command: /usr/bin/echo "No postprocessing in place for training ensemble"
[18-02-25 15:47:17 :INFO ] - Batch tutorial_south_ensemble completed: 2025-02-18 15:47:17.104734
Removing temporary configuration ./tmp.9ywAtKjEaN.train
This trains based on the processed data, and creates a sub-directory under ensemble/ with the network name that contains each of the ensemble runs. This includes log files for debugging in case of any errors/issues in the training process.
ensemble/
└── tutorial_south_ensemble/
├── tutorial_south_ensemble-0/
│ ├── *.err <-- Error file
│ └── *.out <-- Log file
└── tutorial_south_ensemble-1/
└── ...
The output from the trained network can be found in results/networks. The specifics of what is contained in here is out of scope of this notebook (please see 03.data_and_forecasts.ipynb after running through this notebook), but in general it stores the trained model, and a history of the losses and other metrics.
results/
└── networks/
└── tutorial_south_ensemble/
├── *.h5
├── *.json
└── ...
5. Predict#
In a similar manner to the training script, the run_predict_ensemble script will submit jobs to the HPC. The template corresponding to the prediction run is predict.tmpl.yaml found in the icenet-pipeline repo.
For the ensemble prediction, we define the dates we want to predict for in a csv file. This can be automatically generated from the dataset as follows.
!./loader_test_dates.sh tutorial_pipeline_south | tee testdates.csv
2020-04-01
2020-04-02
First look at the required input arguments for running the prediction ensemble.
!./run_predict_ensemble.sh --help
Usage ./run_predict_ensemble.sh NETWORK DATASET NAME DATEFILE [LOADER]
Many of the command line arguments are the same as with run_train_ensemble listed above.
So to to predict from an ensemble training run, we use:
argument | description | value |
|---|---|---|
NETWORK | Name of trained neural network to use for prediction | tutorial_south_ensemble |
DATASET | Name of dataset: dataset_config.{LOADER}.json | tutorial_pipeline_south |
NAME | Name of output prediction | tutorial_south_ensemble_forecast |
DATEFILE | Dates to predict for | testdates.csv |
LOADER | Name of loader: loader.{LOADER}.json (optional) | - |
# -f: n_filters_factor (matching the value used for training)
# -p: prep bash script (A bash script to run before running the prediction)
!./run_predict_ensemble.sh -f 0.6 -p bashpc.sh tutorial_south_ensemble tutorial_pipeline_south tutorial_south_ensemble_forecast testdates.csv
ARGS: -f 0.6 -p bashpc.sh tutorial_south_ensemble tutorial_pipeline_south tutorial_south_ensemble_forecast testdates.csv
ARGS = -x arg_filter_factor=0.6 arg_prep=bashpc.sh , Leftovers: tutorial_south_ensemble tutorial_pipeline_south tutorial_south_ensemble_forecast testdates.csv
No. of ensemble members: 2
Ensemble members: 42,46
Running model_ensemble ./tmp.Gl4q9pXbyD.predict slurm -x arg_filter_factor=0.6 arg_prep=bashpc.sh
[18-02-25 15:47:37 :INFO ] - Model Ensemble Runner
[18-02-25 15:47:37 :INFO ] - Validated configuration file ./tmp.Gl4q9pXbyD.predict successfully
[18-02-25 15:47:37 :INFO ] - Importing model_ensembler.cluster.slurm
[18-02-25 15:47:37 :INFO ] - Running batcher
[18-02-25 15:47:37 :INFO ] - Start batch: 2025-02-18 15:47:37.579080
[18-02-25 15:47:37 :INFO ] - Running cycle 1
[18-02-25 15:47:37 :INFO ] - Running command: /usr/bin/ln -s ../../data
[18-02-25 15:47:37 :INFO ] - Start run tutorial_south_ensemble_forecast-0 at 2025-02-18 15:47:37.591363
[18-02-25 15:47:37 :INFO ] - rsync -aXE ../template/ /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble_forecast/tutorial_south_ensemble_forecast-0/
[18-02-25 15:47:37 :INFO ] - Start run tutorial_south_ensemble_forecast-1 at 2025-02-18 15:47:37.597041
[18-02-25 15:47:37 :INFO ] - rsync -aXE ../template/ /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble_forecast/tutorial_south_ensemble_forecast-1/
[18-02-25 15:47:37 :INFO ] - Templating /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble_forecast/tutorial_south_ensemble_forecast-1/icenet_predict.sh.j2 to /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble_forecast/tutorial_south_ensemble_forecast-1/icenet_predict.sh
[18-02-25 15:47:37 :INFO ] - Templating /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble_forecast/tutorial_south_ensemble_forecast-0/icenet_predict.sh.j2 to /data/hpcdata/users/bryald/git/icenet/icenet/green/ensemble/tutorial_south_ensemble_forecast/tutorial_south_ensemble_forecast-0/icenet_predict.sh
[18-02-25 15:47:37 :INFO ] - Submitted job with ID 6288962
[18-02-25 15:47:37 :INFO ] - Submitted job with ID 6288963
[18-02-25 15:47:37 :WARNING ] - Could not retrieve job from list
[18-02-25 15:47:37 :WARNING ] - Could not retrieve job from list
[18-02-25 15:53:08 :INFO ] - tutorial_south_ensemble_forecast-0 monitor got state COMPLETED for job 6288963
[18-02-25 15:53:08 :INFO ] - End run tutorial_south_ensemble_forecast-0 at 2025-02-18 15:53:08.924486
[18-02-25 15:53:08 :INFO ] - tutorial_south_ensemble_forecast-1 monitor got state COMPLETED for job 6288962
[18-02-25 15:53:08 :INFO ] - End run tutorial_south_ensemble_forecast-1 at 2025-02-18 15:53:08.925093
[18-02-25 15:53:08 :INFO ] - Running command: icenet_output -m --nan -r ../.. -o ../../results/predict tutorial_south_ensemble_forecast tutorial_pipeline_south predict_dates.csv
[18-02-25 15:53:32 :INFO ] - Batch tutorial_south_ensemble_forecast completed: 2025-02-18 15:53:32.850729
Removing temporary configuration ./tmp.Gl4q9pXbyD.predict
As with the previous example, the individual numpy outputs, samples and sample weights are deposited into /results/predict for each ensemble member. However, the ensemble also runs icenet_output to generate a CF-compliant NetCDF containing the forecasts requested which can then be post-processed or deposited to an external location (which is the platform for the wider IceNet forecasting infrastructure).
# Numpy files location (under each ensemble directory listed in the output of this cell)
!ls ./results/predict/tutorial_south_ensemble_forecast
tutorial_south_ensemble.42 tutorial_south_ensemble.46
# Combined netCDF file location
!ls ./results/predict/tutorial_south_ensemble_forecast.nc
./results/predict/tutorial_south_ensemble_forecast.nc
6. Visualisation#
View the forecast output from the pipeline#
Now that we have a prediction, we can visualise the binary sea ice concentration using some of the built-in tools in IceNet that utilise cartopy and matplotlib.
(Note: There are also some scripts in the icenet-pipeline repository that enable plotting common results such as produce_op_assets.sh)
Here, we are loading the prediction netCDF file we’ve just created in the previous step.
We are also using the Masks class from IceNet to create a land mask region that will mask out the land regions in the forecast plot.
from icenet.plotting.video import xarray_to_video as xvid
from icenet.data.sic.mask import Masks
from IPython.display import HTML
import xarray as xr, pandas as pd, datetime as dt
# Load our output prediction file
ds = xr.open_dataset("results/predict/tutorial_south_ensemble_forecast.nc")
land_mask = Masks(south=True, north=False).get_land_mask()
ds.info()
xarray.Dataset {
dimensions:
time = 2 ;
yc = 432 ;
xc = 432 ;
leadtime = 7 ;
variables:
int32 Lambert_Azimuthal_Grid() ;
Lambert_Azimuthal_Grid:grid_mapping_name = lambert_azimuthal_equal_area ;
Lambert_Azimuthal_Grid:longitude_of_projection_origin = 0.0 ;
Lambert_Azimuthal_Grid:latitude_of_projection_origin = -90.0 ;
Lambert_Azimuthal_Grid:false_easting = 0.0 ;
Lambert_Azimuthal_Grid:false_northing = 0.0 ;
Lambert_Azimuthal_Grid:semi_major_axis = 6378137.0 ;
Lambert_Azimuthal_Grid:inverse_flattening = 298.257223563 ;
Lambert_Azimuthal_Grid:proj4_string = +proj=laea +lon_0=0 +datum=WGS84 +ellps=WGS84 +lat_0=-90.0 ;
float32 sic_mean(time, yc, xc, leadtime) ;
sic_mean:long_name = mean sea ice area fraction across ensemble runs of icenet model ;
sic_mean:standard_name = sea_ice_area_fraction ;
sic_mean:short_name = sic ;
sic_mean:valid_min = 0 ;
sic_mean:valid_max = 1 ;
sic_mean:ancillary_variables = sic_stddev ;
sic_mean:grid_mapping = Lambert_Azimuthal_Grid ;
sic_mean:units = 1 ;
float32 sic_stddev(time, yc, xc, leadtime) ;
sic_stddev:long_name = total uncertainty (one standard deviation) of concentration of sea ice ;
sic_stddev:standard_name = sea_ice_area_fraction standard_error ;
sic_stddev:valid_min = 0 ;
sic_stddev:valid_max = 1 ;
sic_stddev:grid_mapping = Lambert_Azimuthal_Grid ;
sic_stddev:units = 1 ;
int64 ensemble_members(time) ;
ensemble_members:long_name = number of ensemble members used to create this prediction ;
ensemble_members:short_name = ensemble_members ;
datetime64[ns] time(time) ;
time:long_name = reference time of product ;
time:standard_name = time ;
time:axis = T ;
int64 leadtime(leadtime) ;
leadtime:long_name = leadtime of forecast in relation to reference time ;
leadtime:short_name = leadtime ;
datetime64[ns] forecast_date(time, leadtime) ;
float64 xc(xc) ;
xc:long_name = x coordinate of projection (eastings) ;
xc:standard_name = projection_x_coordinate ;
xc:units = 1000 meter ;
xc:axis = X ;
float64 yc(yc) ;
yc:long_name = y coordinate of projection (northings) ;
yc:standard_name = projection_y_coordinate ;
yc:units = 1000 meter ;
yc:axis = Y ;
float32 lat(yc, xc) ;
lat:long_name = latitude coordinate ;
lat:standard_name = latitude ;
lat:units = arc_degree ;
float32 lon(yc, xc) ;
lon:long_name = longitude coordinate ;
lon:standard_name = longitude ;
lon:units = arc_degree ;
// global attributes:
:Conventions = CF-1.6 ACDD-1.3 ;
:comments = ;
:creator_email = jambyr@bas.ac.uk ;
:creator_institution = British Antarctic Survey ;
:creator_name = James Byrne ;
:creator_url = www.bas.ac.uk ;
:date_created = 2025-02-18 ;
:geospatial_bounds_crs = EPSG:6932 ;
:geospatial_lat_min = -90.0 ;
:geospatial_lat_max = -16.62393 ;
:geospatial_lon_min = -180.0 ;
:geospatial_lon_max = 180.0 ;
:geospatial_vertical_min = 0.0 ;
:geospatial_vertical_max = 0.0 ;
:history = 2025-02-18 15:53:31.886924 - creation ;
:id = IceNet 0.2.9_dev ;
:institution = British Antarctic Survey ;
:keywords = 'Earth Science > Cryosphere > Sea Ice > Sea Ice Concentration
Earth Science > Oceans > Sea Ice > Sea Ice Concentration
Earth Science > Climate Indicators > Cryospheric Indicators > Sea Ice
Geographic Region > Southern Hemisphere ;
:keywords_vocabulary = GCMD Science Keywords ;
:license = Open Government Licece (OGL) V3 ;
:naming_authority = uk.ac.bas ;
:platform = BAS HPC ;
:product_version = 0.2.9_dev ;
:project = IceNet ;
:publisher_email = ;
:publisher_institution = British Antarctic Survey ;
:publisher_url = ;
:source =
IceNet model generation at v0.2.9_dev
;
:spatial_resolution = 25.0 km grid spacing ;
:standard_name_vocabulary = CF Standard Name Table v27 ;
:summary =
This is an output of sea ice concentration predictions from the
IceNet run in an ensemble, with postprocessing to determine
the mean and standard deviation across the runs.
;
:time_coverage_start = 2020-04-02T00:00:00 ;
:time_coverage_end = 2020-04-09T00:00:00 ;
:time_coverage_duration = P1D ;
:time_coverage_resolution = P1D ;
:title = Sea Ice Concentration Prediction ;
}
The next cell obtains the start date of the forecast
# Get the forecast start date
forecast_date = ds.time.values[0]
print(forecast_date)
2020-04-01T00:00:00.000000000
And, here, we plot the forecast across the range of days we’ve defined within the ENVS file (7 days in this case).
Since this is a demonstrator notebook, we have not trained our network for a prolonged period of time or for a large date range, but the plot below shows indicative results of what the output would look like.
fc = ds.sic_mean.isel(time=0).drop_vars("time").rename(dict(leadtime="time"))
fc['time'] = [pd.to_datetime(forecast_date) \
+ dt.timedelta(days=int(e)) for e in fc.time.values]
anim = xvid(fc, 15, figsize=(4, 4), mask=land_mask, north=False, south=True)
HTML(anim.to_jshtml())
There are more plotting related options available using the produce_op_assets.sh script which will package up the forecast outputs which will include geotiffs, netCDF, png, and mp4 and be placed in results/forecasts/ as operational forecasts. The help in the script is descriptive and includes examples, hence, it is not covered in this notebook.
!./produce_op_assets.sh --help
Usage: ./produce_op_assets.sh [options] <forecast name w/hemi> [region]
Generate forecast outputs from netCDF prediction file (Outputs: geotiff, png, mp4)
Outputs to 'results/forecast/<forecast name w/hemi>'
Positional arguments:
name Name of the prediction netCDF file, with hemisphere postfix ('_south'), e.g. 'forecastfile_south'.
This file is found under 'results/predict/'
region Region to clip. If prefixed with 'l', will use lon/lat, else, pixel bounds.
* Specify via 'x_min,y_min,x_max,y_max' if using pixel bounds.
* Specify via 'llon_min,lat_min,lon_max,lat_max' if using lon/lat bounds (Notice the prefix 'l', see example below).
Optional arguments:
-c Cartopy CRS to use for plotting forecasts (e.g. Mercator).
-h Show this help message and exit.
-l Integer defining max leadtime to generate outputs for.
-n Clip the data to the region specified by lon/lat, will cause empty pixels across image edges due to lon/lat curvature.
-v Enable verbose mode - debugging print of commands.
Examples:
1) ./produce_op_assets.sh -v
Runs script in verbose mode, in this case, just prints help.
2) ./produce_op_assets.sh fc.2024-05-21_north 70,155,145,240
Produce outputs from './results/predict/fc.2024-05-21_north.nc'
and crop to only the pixel region of x_min=70, y_min=155, x_max=145, y_max=240.
3) ./produce_op_assets.sh fc.2024-05-21_north l-100,55,-70,75
Produce outputs from './results/predict/fc.2024-05-21_north.nc'
and crop to lon/lat region of lon_min=-100, lat_min=55, lon_max=-70, lat_max=75
and changing the plot extents to the defined lon/lat region.
4) ./produce_op_assets.sh -n fc.2024-05-21_north l-100,55,-70,75
Same as 3), but clipping source data to lon/lat bounds.
Clips data to lon/lat region of lon_min=-100, lat_min=55, lon_max=-70, lat_max=75
before plotting.
Can have missing pixels by boundaries depending on projection selected.
5) ./produce_op_assets.sh -n -c Mercator.GOOGLE fc.2024-05-21_north l-100,55,-70,75
Same as 4), but outputs using Web Mercator for plots instead of polar equal area.
Other Pipeline Considerations#
A bit more information on ensemble runs#
Cleaning up runs#
Ensemble runs take place under /ensemble/ in the pipeline folder and ARE NOT deleted after they’ve happened, to allow for debugging. Commonly, the ensemble configurations will contain a delete task to remove the extraneous run folders. In the meantime this should be done manually after running run_train_ensemble or run_predict_ensemble.
The only exception to this is the use of run_daily.sh (see below) which does clean up prior to rerunning.
Daily execution#
Daily execution is facilitated in the pipeline by using run_daily.sh. This wraps all the necessary steps to perform the following sequence for producing forecasts from yesterday for the next 93 days, for both northern and southern hemispheres.
Removes any old ensemble runs
Processes the HRES and necessary training metadata to produce a data loader
Creates a dataset configuration for it
Runs a prediction ensemble to produce a NetCDF
Uploads to the necessary endpoint
Automation#
With the above shell script it’s trivial to automate using cron. Of course this is simply for demonstration, with more complex workflow managers offering far great flexibility especially when considering analysis of the produced forecasts.
# We assume your environment is configured appropriately to run conda from cron files, for example by adding...
#
# SHELL=/bin/bash
# BASH_ENV=~/.bashrc_env
#
# With conda initialisation in bashrc_env at the top of your crontab
25 9 * * * conda activate icenet; cd $HOME/hpc/icenet/pipeline && bash run_daily.sh >$HOME/daily.log 2>&1; conda deactivate
TODO: more information on the usage of this command.
Summary#
Within this notebook we’ve attempted to give a full crash course on the IceNet pipeline and how to utilise it for a generalised run using the pipeline helper scripts. This is the second of the introductory notebooks, to cover further information:
Data structure and analysis
03.data_and_forecasts.ipynb: understand the structure of the data stores and products created by these workflows and what tools currently exist in IceNet to looks over them.
Library usage
04.library_usage.ipynb: understand how to programmatically perform an end to end run.
Version#
IceNet Codebase: v0.2.9